hcnak.blog
posted at 2015-10-18 23:29:56 +0000
C++实现将文件二进位制作为字符串读出与写入字符串形式的二进制数据
本文说明如何利用C++将文件的二进制数据,作为字符串读出。
文章末尾我给出了这个算法的C++完整实现。
并将给定字符串形式的二进制数据写入文件的一种可行方法。举例:
将文件二进制位读出:
00010001011110001
将以上字符串形式的二进制数据,再写入文件
一旦我们有了这个,对于一些小的文件,我们可以用来分析文件格式啥的。
读取文件的二进制位
首先将读取吧,C++这类语言都提供了按位运算符(&,|,^),所以我们要用这个运算符。
对于所有文件,有一点我们是可以保证的,它的二进制位都是8的整数倍。
读取二进制的话,我们首先需要一个变量作为容器。这里我以 short 类型的变量作为读取容器。
当然,因为 short 类型的定义是_no smaller than 16 bits_,所以我们需要一个一个变量来储存是否有未读满的short类型。至于如何做,我建议在进行正式读取文件之前,我们再用fstream打开的时候将文件指针移动到文件尾部,最后利用fstream::tellg()得到它的位置L(单位byte),然后用sizeof得到当前环境下的short字节长度Z,最后取余(L%Z)得到的就是最后一个读入的short容器的空闲位(即没有读入文件数据的位数).就像这样:
ifstream read(filepath, ios_base::binary | ios_base::in | ios_base::ate); //open specfic file,then move pointer to the end of file
int fileylen = read.tellg(); //tell the len of the file (bytes)
read.seekg(0, ios_base::beg); //set pointer to the begining of the file
文件IO的话,当然是用 fstream的 read()函数,将文件作为二进制打开。然后我们用一个循环不断的读取一个个short,然后做按位与运算。所以我们需要定义一个short数组,这个数组里面储存的元素都只有一个位为 1 ,且为1的位各不相同。就像这样:
short SV[16] = { short(0x1),short(0x2),short(0x4),short(0x8),
short(0x10),short(0x20),short(0x40),short(0x80),
short(0x100),short(0x200),short(0x400),short(0x800),
short(0x1000),short(0x2000),short(0x4000),short(0x8000)
};
每次我们从文件中读出一个short (sbuf),就拿来把它的每一位和上面的SV数组的一个个元素做按位与运算,如下:
for (int m = 0; m < sizeof(short); m++)
{
if ((sbuf & SV[m]) == SV[m])
{
binBuf += "1";
}
else
{
binBuf += "0";
}
}
要是该位为1的话,值自然不会变啦 xD 我们把每次读出的 0和1放入到binBuf这个string对象里面,最后输出就行了
根据已有字符串形式的二进制数写入
接下来我们讲讲根据已有字符串形式的二进制数据,来恢复数据的过程。 很明显,读出数据的时候我们用的按位与运算,写入数据的时候我们自然就应该用按位或运算啦 xD 同读入部分,我们还是用一个short变量作为容器,只不过,每次操作完并将这个变量写入文件后,我们应该将这个缓冲变量的值设置为0(这样的话,它的每一位都未0)。 我们还是需要先确定给定的字符串形式二进制数据可以装满多少个short变量,仍然需要记录最后一个short变量的空闲位。 在写入的时候,每次用fstream::write()函数写入一个short值,再将缓冲short值设置为0,如此往复,直到全部写完,代码如下:
for (int m = 0; m < sizeof(short); m++)
{
if (binBuf[m] == '1') //now set the bit of short
{
sbuf = (sbuf | SV[m]);
}
}
write.write((char*)&sbuf, sizeof(short));
sbuf = 0; //set all bits to 0
读取顺序
我这里提出的是使用 fstream的read()和write()函数来进行读取,如果读者使用我在后面提到的 fread()函数,请一定要配合fwrite()函数使用,配合 fstream::write()的话,可能会遇到意想不到的问题。
关于读取出来的二进制顺序,是这样的:
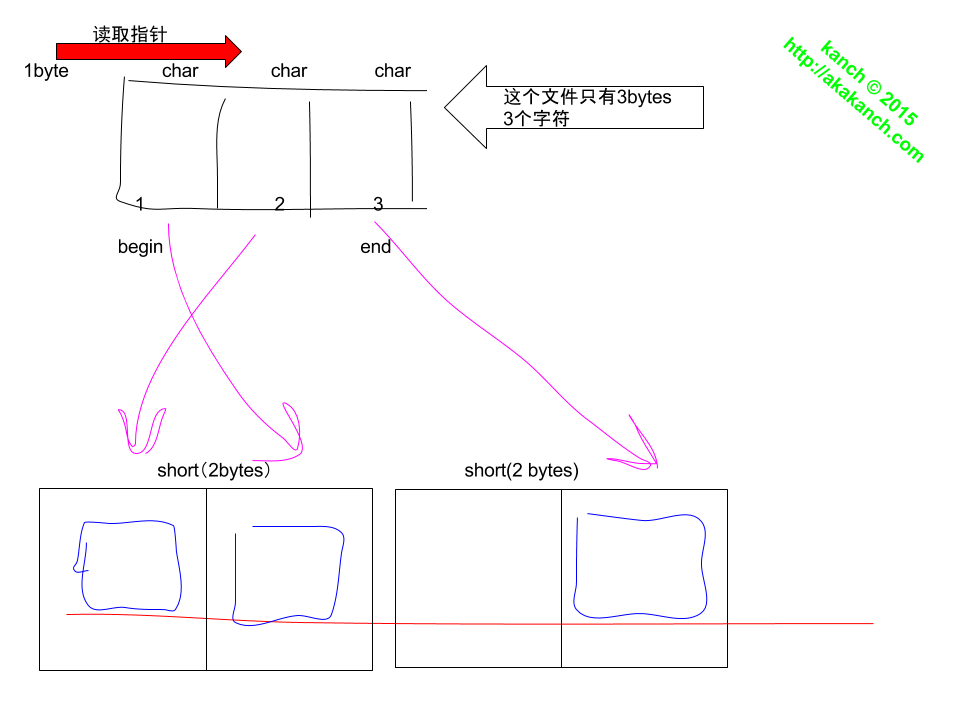
关于算法效率的问题
但是这样的话如果我们用一个个short 类型作为容器,当文件大一点的时候,效率会很低(因为是顺序读取,还可考虑并行分块读取~2019更新)。
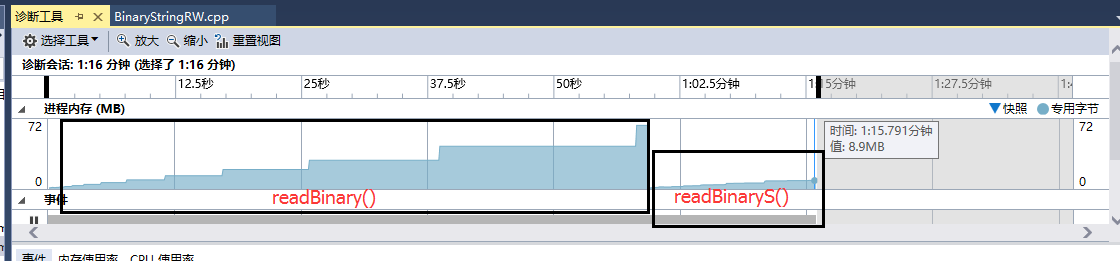
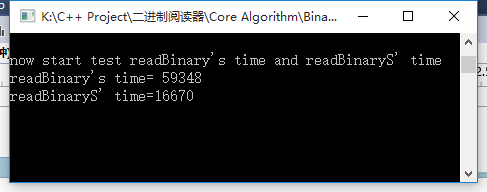
所以,我们也可以使用 fopen()打开文件,然后用 fread()来读取文件,当然,如果这样的话,我们就需要用char数组作为一个缓冲区。我做个一个计算,fread()的效率,要远远大于fstream的read()。下面是我当时测试的时候用的数据:
我用了fread()函数后,效率提高了好多,内存占用量也少了好多。我用fread()每次将数据从文件中读入一个12000字节的char缓冲区。输出的时间以毫秒为单位,以5.47MB的jpg文件作为测试文件:之前的方法用了59s,内存峰值70+MB;改用fread()后用时16s,内存峰值8MB。
除此之外,还可以利用多线程和C++内嵌汇编来提高效率。
所以,还请读者去我的GitHub页面,大家一起完成这个算法,让它效率更高 xD
该算法(BinaryStringRW)的具体实现请访问我的GitHub页面:https://github.com/ankanch/BinaryStringRW
**<转载请注明出处>**
© kanch → zl AT kanchz DOT com
last updated on 2022-07-27 01:57:54 +0000