hcnak.blog
posted at 2016-09-28 12:51:05 +0000
不到20行简单Python代码获取有道翻译的翻译结果
Python真是一个牛逼的脚本语言。
接下来我来谈谈这个小程序,一个不到20行核心代码的小程序,用户输入对应的英文字母,我们返回相应的中文翻译,当然,中文翻译来自有道翻译。
接下来进入正题。
简单的讲,获取翻译结果就是将目标网页下载下来,然后进行字符串匹配,从网页源代码中匹配出翻译结果就行。
如下图所示:
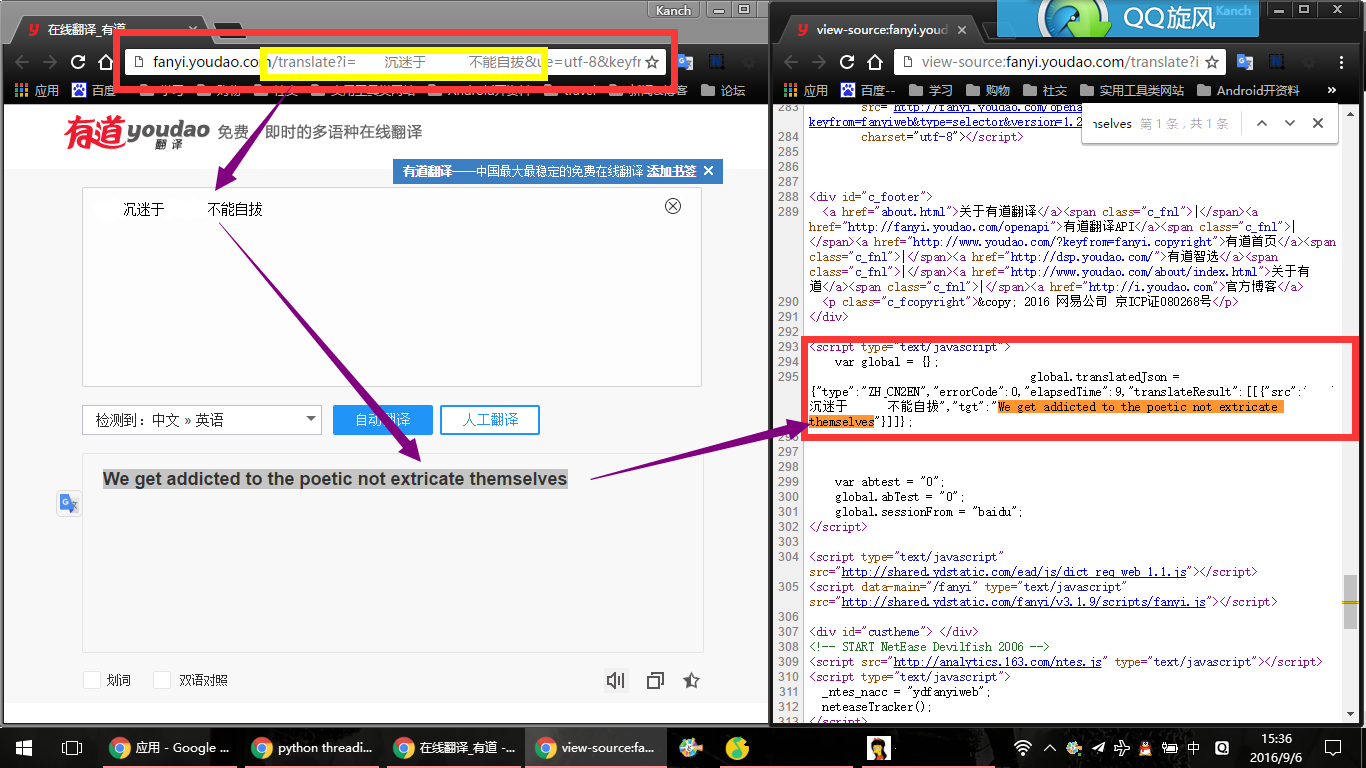
我们首先打开有道翻译,然后随便翻译点什么,然后,观察url的变化,因为之后我们需要通过这个url来构造我们的翻译查询url:
query_url="http://fanyi.youdao.com/translate?ue=utf-8&keyfrom=baidu&smartresult=dict&type=EN2ZH_CN&i=" + word #word是要翻译的单词
比如我可以看到,这串翻译结果,前面的字符串是 “tgt”:” 后面的是”}]],,简直奇葩,可以保证只有一个。
所以,整个流程应该是:
构造翻译url -> 下载对应的网页 -> 从对应的网页里匹配出字符串
下载网页,我们可以通过urllib的urlopen和read实现。
page = urllib.request.urlopen(url,timeout=5) html = page.read() html = getHtml(url) html = html.decode('utf-8','ignore') #解码,一定要加上ignore标签,否则可能会出错
head = "\"tgt\":\"" tail = "\"}]]," start = html.find(head) end = html.find(tail,start) result1 = html[start+len(head):end]
如果只提取一个中文意思,且不包括其它附加信息的话,核心代码就只有10行。
#coding=utf-8
import urllib.request
import urllib.parse
import re
query_url="[http://fanyi.youdao.com/translate?ue=utf-8&keyfrom=baidu&smartresult=dict&type=EN2ZH_CN&i=](http://fanyi.youdao.com/translate?ue=utf-8&keyfrom=baidu&smartresult=dict&type=EN2ZH_CN&i=)"
def getHtml(url):
page = urllib.request.urlopen(url,timeout=5)
html = page.read()
return html
def getTranslate(word,query_url):
#url = query_url + urllib.parse.urlparse(word)
url = query_url + word
html = getHtml(url)
html = html.decode('utf-8','ignore')
#寻找翻译结果
head = "\"tgt\":\""
tail = "\"}]],"
start = html.find(head)
end = html.find(tail,start)
result1 = html[start+len(head):end]
#寻找附加结果
head ="[\"\",\""
tail ="\"]}};"
start = html.find(head)
end = html.find(tail,start)
result2 = html[start+len(head):end]
print('\r\n\r\n',word,'\r\n',result1,'\r\n',result2,'\r\n\r\n\r\n')
word = "11111"
while(word != "EEXXIITT"):
word = input("enter a word(ENGLISH -> CHINESE) : **_**\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b")
getTranslate(word,query_url)
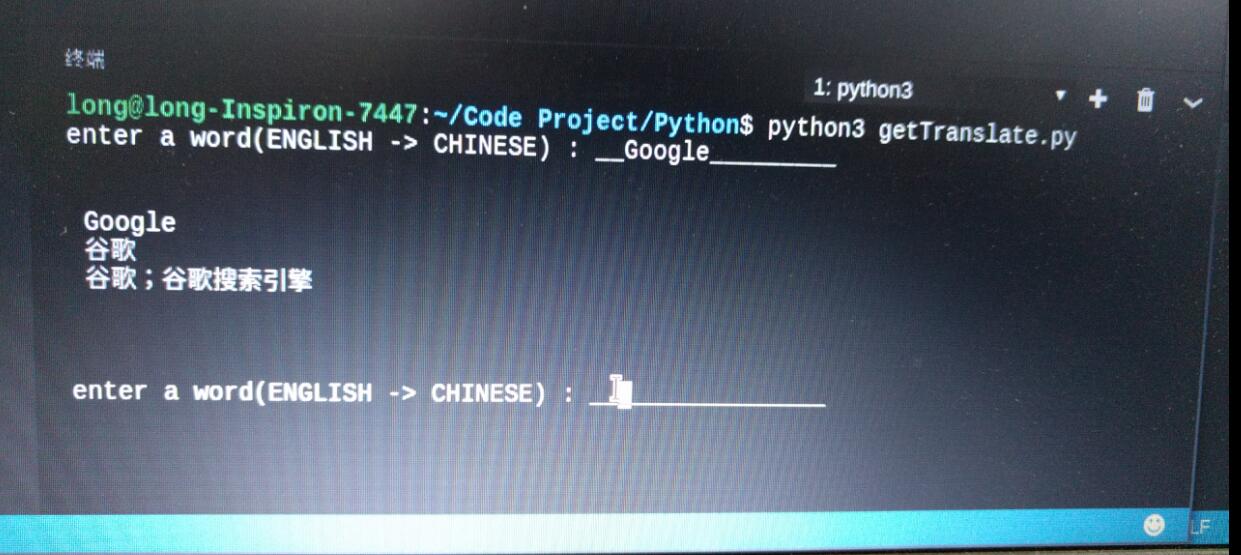
运行结果:
© kanch → zl AT kanchz DOT com
last updated on 2022-07-27 01:57:54 +0000