hcnak.blog
posted at 2017-03-12 16:16:46 +0000
成都信息工程大学四六级成绩分析 - 从数据获取到分析数据
0.概要
这篇文章对成都信息工程大学的四六级的成绩进行了分析。这篇文章涵盖了从数据的获取,到储存,到数据的分析。全文读完大概需要 20 分钟。
所有的数据通过合法途径且可公开获取,详细说明见文章末尾。
该文章涉及的所有数据,源代码均可在我的gihub账户下的 data analysis仓库获得,点击如下按钮即可下载:
1.数据的获取
为了分析四六级数据,首先我们需要获取数据。我们学校的教务处网站已经提供了通过学生姓名查询四六级成绩的功能(点击这里跳转至教务处)。
我们只需要写一个简单的脚本遍历查询学生的姓名即可。为了获得学生姓名,我们也可以通过教务处网站的班级学生名单获得全校的学生名单(点击这里跳转,需要登录)。
接下来讲讲如何写脚本来获取四六级数据。
打开前面提到的教务处查询四六级的网站,我们可以看到只需要输入名字就可以查询到,而且URL并没有发生改变,网页源代码里面也没有js来提交数据。故这个页面只是简单的使用了HTML的表单来post数据到后端。
接下来我们用Fiddler抓包(Chrome的F12开发者模式也可以)。为了完全模仿新用户的行为,我们打开一个Chrome的隐身标签,然后访问该网站。我们可以看到,如下图所示:
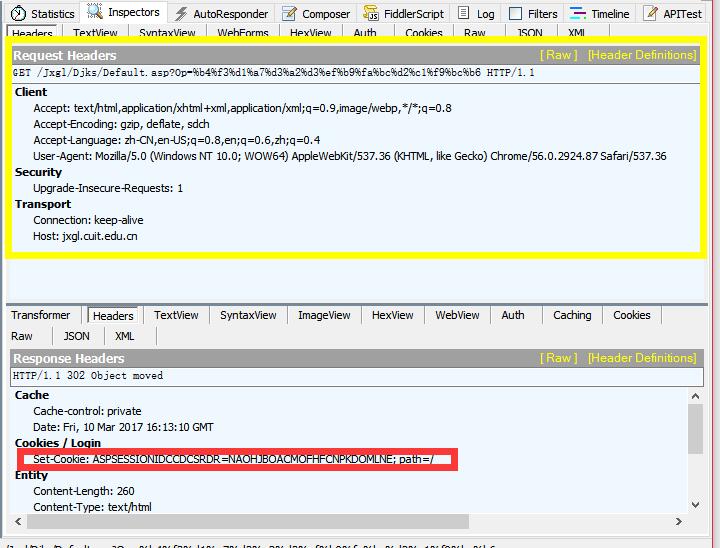
访问过程中发生了2次302重定向和2次200状态吗。其中有用的只有第一次,如上图所示。第一次302响应为我们设置了一个叫做ASPSESSIONIDCCDCSRDR的Cookies。后面通过构造post发现,如果带有错误的该项cookies或者无该项Cookies,都不能正常的请求到成绩数据。
故我们有了第一步,那就是需要先向这个页面发送GET请求来获取一个叫做ASPSESSIONIDCCDCSRDR的Cookies,然后之后构造的Post请求都需要带上这个Cookies。
Python下我们通过以下代码来获取一个cookies并永久保存用于之后的查询:
通过Python Rquests包的session来永久的保存一个Cookies集合。
import requests
# 用于请求cookies
header = { 'Host': 'jxgl.cuit.edu.cn', 'Connection': 'keep-alive', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,__;q=0.8', 'Accept-Encoding': 'gzip, deflate, sdch', 'Accept-Language': 'zh-CN,en-US;q=0.8,en;q=0.6,zh;q=0.4' }
## 获取必要session
session = requests.Session() session.get("http://jxgl.cuit.edu.cn/Jxgl/Djks/Default.asp?Op=%B4%F3%D1%A7%D3%A2%D3%EF%B9%FA%BC%D2%C1%F9%BC%B6",headers=header)
print(session.cookies.get_dict())
接下来我们继续分析。我们继续抓包,这次我们抓取当我们在查询页面输入学生姓名然后点击查询的时候,浏览器发送的数据包。
Fiddler抓包信息如下:
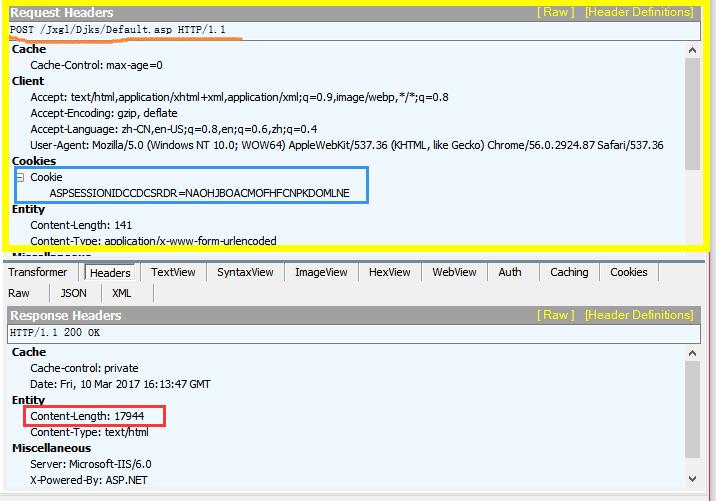
从上图可以看出,在post查询请求的时候,带上了ASPSESSIONIDCCDCSRDR这个Cookies,另外再看服务器响应的该查询请求,响应长度为12944,这说明正确返回了所需要的信息。如果这个值太小(比如1000左右),有可能是返回了其他页面,即我们构造post请求失败。
再看下面这张图,下面这张图是当我们向服务器发送查询命令的时候浏览器发送给服务器的表单数据。通过分析,我们发现,图中1,2,3分别指定了查询的成绩类型,学生姓名和查询的考试时间。
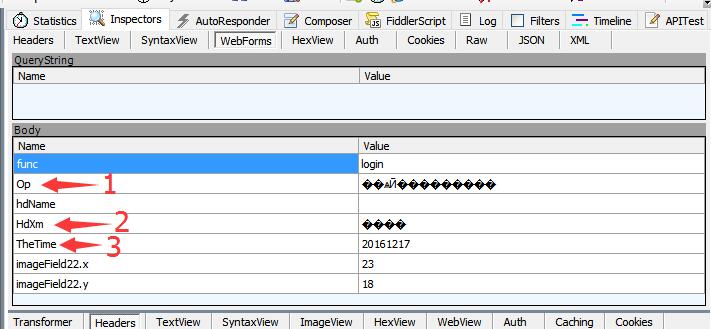
上图的源数据如下:
func=login&Op=%B4%F3%D1%A7%D3%A2%D3%EF%B9%FA%BC%D2%C1%F9%BC%B6&hdName=&HdXm=%D5%C5%C1%FA&TheTime=20161217&imageField22.x=23&imageField22.y=18
通过以下Python代码实现构造查询用的header进行学生成绩查询(需要结合上面提到的代码):
#用于请求成绩的header
headerget = { 'Host': 'jxgl.cuit.edu.cn', 'Connection': 'keep-alive', 'Content-Length': '140', 'Cache-Control': 'max-age=0', 'Origin': 'http://jxgl.cuit.edu.cn', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36', 'Content-Type': 'application/x-www-form-urlencoded', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,__;q=0.8','Referer': 'http://jxgl.cuit.edu.cn/Jxgl/Djks/Default.asp?Op=%B4%F3%D1%A7%D3%A2%D3%EF%B9%FA%BC%D2%C1%F9%BC%B6',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,en-US;q=0.8,en;q=0.6,zh;q=0.4'
}
#用于查询的字段
sdata = { "func":"login", 'Op':'大学英语国家六级'.encode('GB2312'), 'hdName':'', 'HdXm':"张龙".encode('GB2312'), 'TheTime':20161217, 'imageField22.x':18, 'imageField22.y':13 }
# 发送查询post请求
r = session.post("http://jxgl.cuit.edu.cn/Jxgl/Djks/Default.asp", data=sdata,headers=headerget)
# 对结果进行再编码,这里是为了防止中文乱码
shtml = r.text.encode(r.encoding).decode('GB2312','ignore')
最后,由于教务处查询后返回的是网页,而不是易于处理的结构化数据,所以,我们再用bs4匹配一次即可。(当存在同名学生的时候,查询条件会不止一条,这时候我们需要通过学号来限制(详细请参阅代码))
2.数据的储存
对于数据储存,由于一个学生可能考了多次四六级,故我采用了以下结构来储存数据:
[学号,考号,姓名,班级, [[成绩1:考试时间,类型,缺考,总分,听力,阅读,写作],[成绩2:考试时间,类型,总分,听力,阅读,写作]] ] </div> 示例:
[ 201305103*, #学号 51006016220763*, #考号 学生姓名, 计算机(工程)131, #班级 [ #成绩列表,list ['20160618', '大学英语国家四级', '', '439', '195', '109', '135'], ['20151219', '大学英语国家四级', '', '419', '134', '156', '129'], ['20150613', '大学英语国家四级', '', '383', '147', '119', '117'], ['20141220', '大学英语国家四级', '', '341', '134', '90', '117'], ['20161217', '大学英语国家六级', '', '278', '112', '128', '38'] ]
3.数据的分析
数据处理
接下来,我们进入数据分析环节。在这里,为了便于跟踪,我们拿计算机学院2013级为例。
为什么要选2013级?
2013级目前大四(本文写于2017年),相当于每一年都有四六级成绩(如果考了六级)。数据量充足,且方便规律总结。
在从教务处下载计算机2013级名单且查询完毕四六级后,我们一共得到大概900条数据数据。(计算机学院2013级一共才200余人)。
接下来我们需要通过下面这个脚本生成上一节提到的按照学生存放的数据结构。
import csv
CET4 = "大学英语国家四级" CET6 = "大学英语国家六级"
# 加载记录集
stulist = []
f = open('result.csv','r')
csvr = csv.reader(f)
for line in csvr:
if len(line) > 1:
#print(line)
stulist.append(line)
f.close()
del stulist[0]
print("数据总数:",len(stulist))
# 处理记录集
sidrl = []
stu46list = [] #储存每一次4,6级成绩的数据 [学号,考号,姓名,班级,[[成绩1:考试时间,类型,缺考,总分,听力,阅读,写作],[成绩2:考试时间,类型,总分,听力,阅读,写作]]
for stu in stulist:
pid = stu[2]
#首先找出一个学生的所有成绩
scl = [ x for x in stulist if x[2]==pid and pid not in sidrl ]
sidrl.append(pid)
if len(scl) <= 0:
if stu[2] in sidrl:
print(stu[3],"已经处理,跳过;")
else:
print(stu[3],"没有考试记录;")
else:
print(scl[0][3],"有",len(scl),"条考试记录;",end='\t')
cet4 = [ x for x in scl if x[11] == CET4 ]
cet6 = [ x for x in scl if x[11] == CET6 ]
print("其中有四级考试",len(cet4),"次,六级考试",len(cet6),"次.",end='\t')
stucetinfo = [stu[2],stu[1],stu[3],stu[7],[ ]]
#插入学生信息数组
for exam in cet4:
stucetinfo[4].append( [ exam[0],exam[11],exam[6],exam[5],exam[8],exam[9],exam[10] ] )
for exam in cet6:
stucetinfo[4].append( [ exam[0],exam[11],exam[6],exam[5],exam[8],exam[9],exam[10] ] )
stu46list.append(stucetinfo)
print("\n---\n原始数据:",len(stulist),"条,独立学生数据:",len(stu46list),"条")
f = open("csCET46list.csv","w") csvw = csv.writer(f) csvw.writerows(stu46list) f.close()
通过对成绩查询结果运行以上代码,我们已经生成了所需要的数据结构。
接下来我们对该结构数据进行分析。
四级分析
我们可以首先分析一下计算机学院2013级学生从开学到现在,每一次四级考试的成绩变化曲线。也就是说对比不同时间进行的四级考试的成绩变化。
我们只需要遍历每一个学生的成绩列表,将对应时间段的四级成绩放入对应时间段的四级成绩列表即可。为了让曲线图更加好看,我们去掉x轴的学生姓名,用编号代替,同时的绘图之前进行一次降序排序,这样变化趋势非常直观。
通过以下代码代码可以实现将每一名学生的四级成绩放到相应的时间段里:
# [ [考试年份1,[ 成绩列表:考试时间,类型,缺考,总分,听力,阅读,写作 ]], [考试年份2,[ 成绩列表:学生信息 ]],[考试年份3,[ 成绩列表:学生信息 ]],...... ]
# 其中 stulist为按照学生存放的成绩列表,exam_season为考试时间列表
CET4SCORE = []
# 构造符合以上条件的结构体
for season in exam_season:
CET4SCORE.append( [ season , [ y for x in stulist for y in x[4] if y[0] == season and y[1] == CET4 ].copy() ] )
接下来我们绘制图像,2013级四级变化曲线如下:
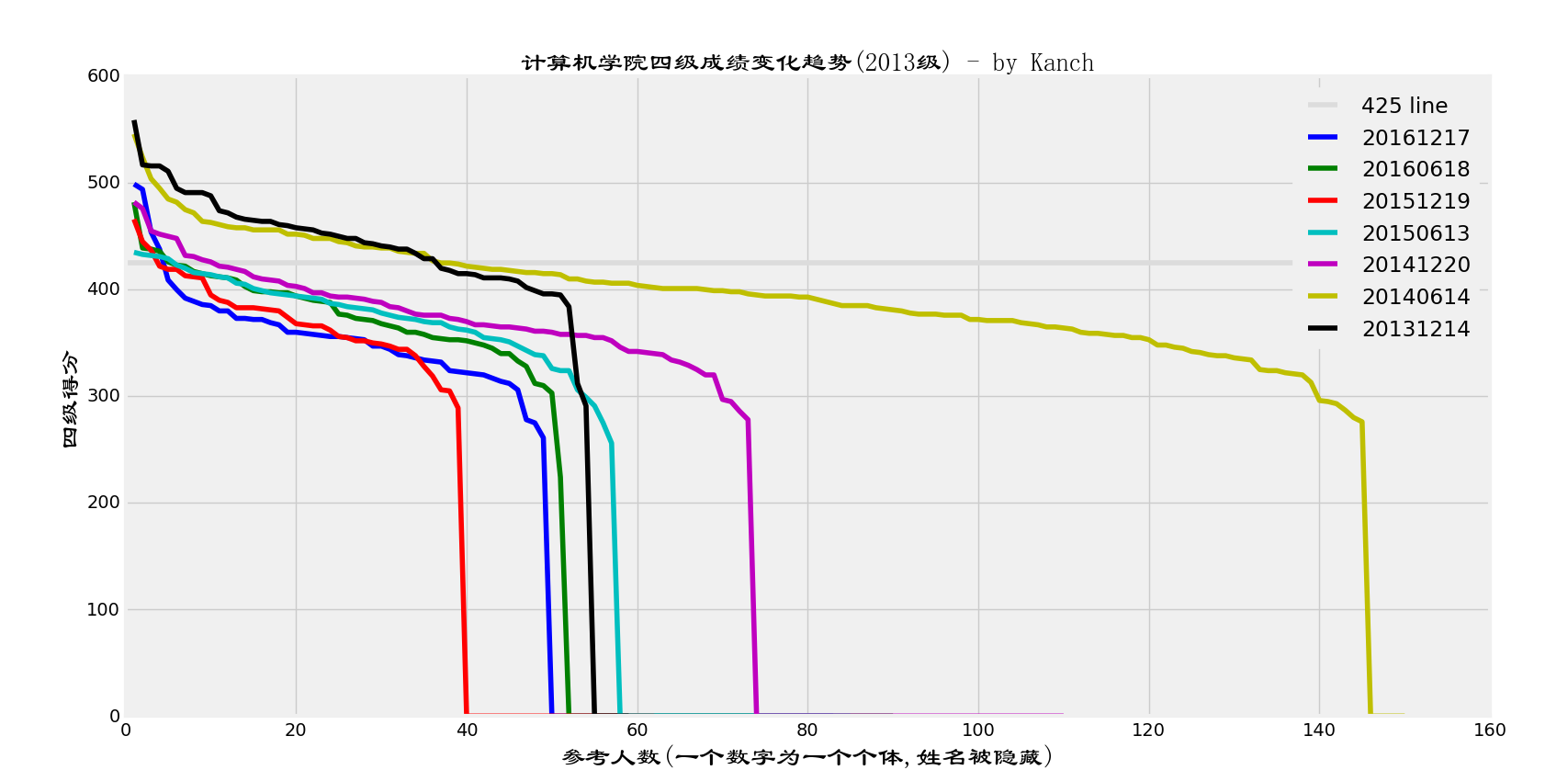
wow,这个成绩变化简直惨不忍睹。上图中我绘制出了425分那条线(浅灰色那条)。
简单的讲就是,从2013级入学到现在,四级考试成绩基本上就一次比一次低。刚开学的时候考四级肯定是最高的,这是符合客观规律的。而且刚开学的时候不是所有人都可以考四级,故,在第二学期,也就是黄线,第二次四级考试人数达到了最高。
我们可以发现,随着四级考试次数的增多,缺考人数也在增加(成绩=0)。
从第三学期开始,2013级基本上全年级都开始进入懈怠状态,这和我们目前2015级的状态也一样。大学前两学期大家都斗志昂扬,基本上从第三学期开始,就有了显著的变化。那就是人越来越懒了。从四级成绩可以明显发现,同时从对期末考试成绩的分析(查看计算机学院2015级第三学期期末分析)也可以发现这一点。
还有一个有趣的情况就是,越到后面,上400都难,基本上大多数人都集中在300->400这个区间。
我们再进一步分析四级数据,我们可以绘制出每一年过级率变化曲线:
仍然借助于上面使用到的CET4SCORE变量,通过以下代码,即可将通过率以及最高成绩,最低成绩放入一个新的list中:
caldata = [] #结构:[考试时间,通过率,最高分,最低分]
for cet4 in CET4SCORE:
#[考试年份1,[ 成绩列表:[考试时间,类型,缺考,总分,听力,阅读,写作] ]]
#通过这个循环,将会得到每一次考试的通过率以及最高成绩,最低成绩
passrate = str(round(len([x[3] for x in cet4[1] if int(x[3])>=425])/len(cet4[1])*100,2))+"%"
maxs = max(cet4[1],key=lambda x:x[3])[3]
rv = [x[3] for x in cet4[1] if x[3] != "0"]
mins = min(rv)
caldata.append([ cet4[0],passrate,maxs,mins ])
caldata.reverse()
print(caldata)
再借助matplotlib,我们便有了下面两张图:
下面这张图是计算机学院2013级四级过级率的变化曲线(分数高于425的人数除以参考人数)
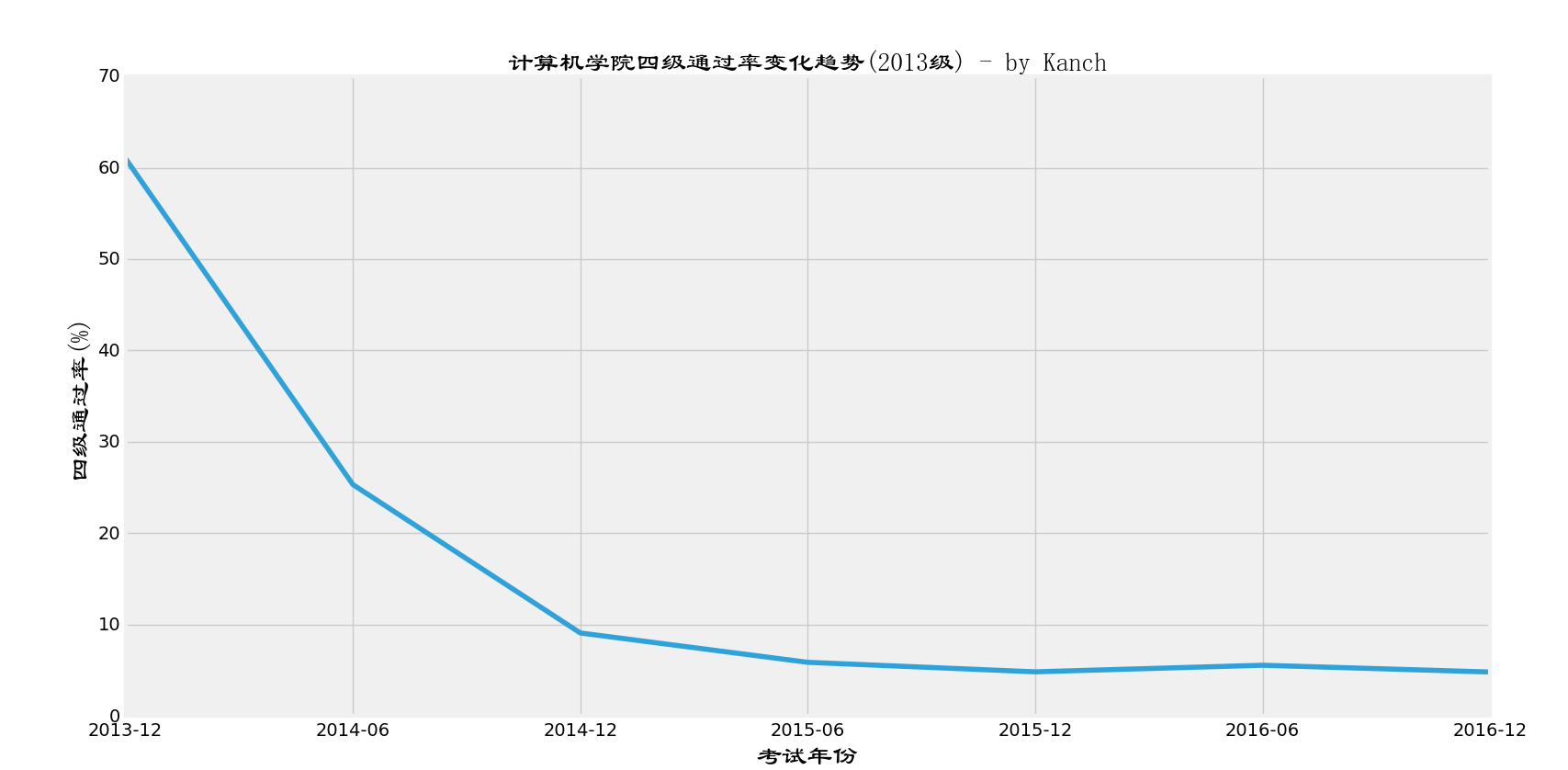
上面这张图充分说明了考试通过率的变化,非常符合我对上张图的分析情况,大家都只有在第一二学期稍微认真一些,一旦大学的新鲜感一过,大家都开始惰散了。目测计算机学院2013级今年毕业的时候还是会有一大堆人还是没有能够通过四级考试。所以呢,我们学校的授位条件没有将425分作为最低条件真是个明智的选择。
接下来这张是四级考试最高分和最低分在历年考试中的变化曲线(最低分不包含0分)
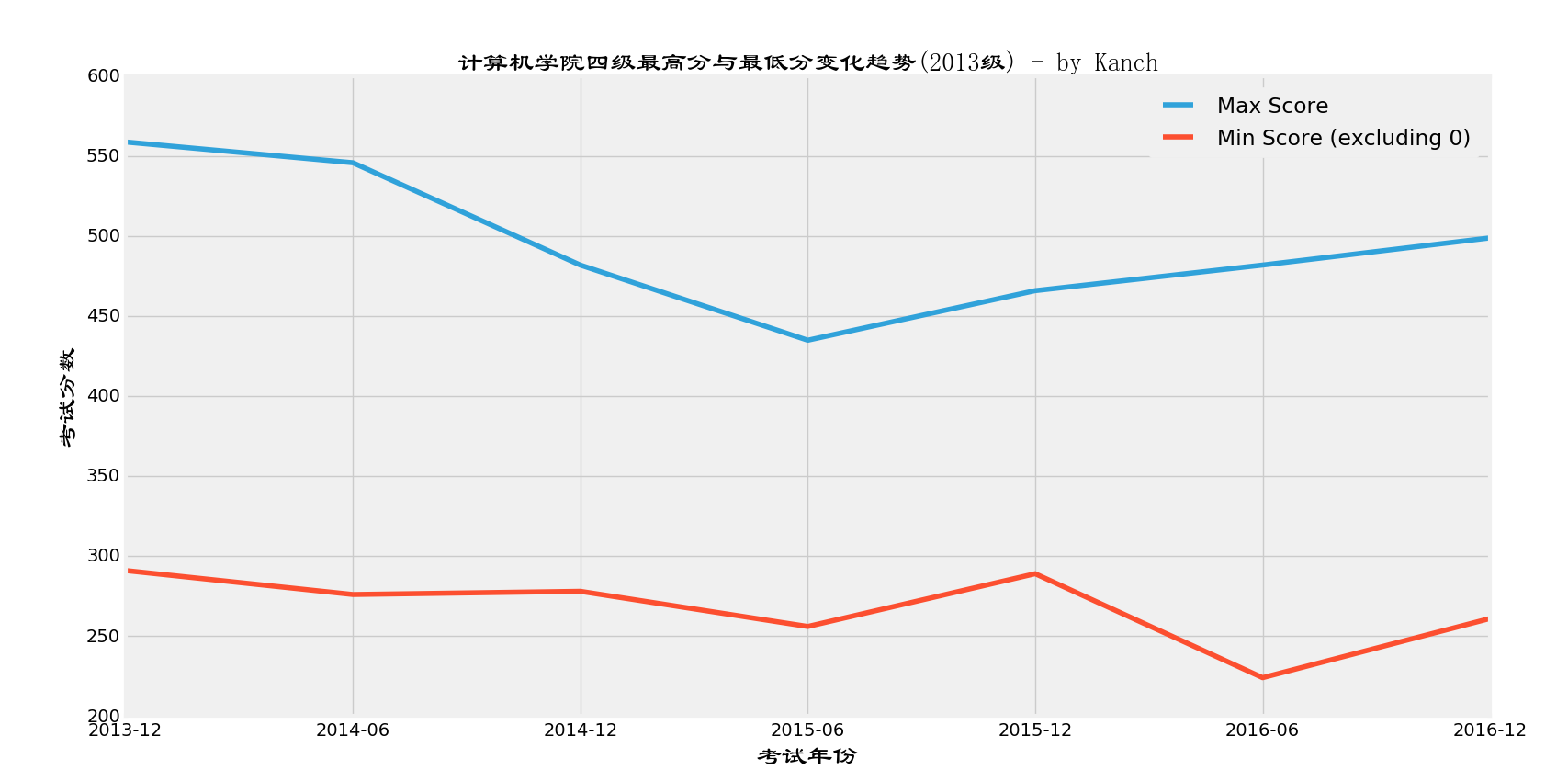 啧啧,我估计越到后面上500越难是因为英语成绩好的/会考试的基本在第一二学期都过了,剩下的在那里挣扎的都是英语不太好的。
啧啧,我估计越到后面上500越难是因为英语成绩好的/会考试的基本在第一二学期都过了,剩下的在那里挣扎的都是英语不太好的。
六级分析
我们用同样的方法也可以得出2013级的六级成绩情况:
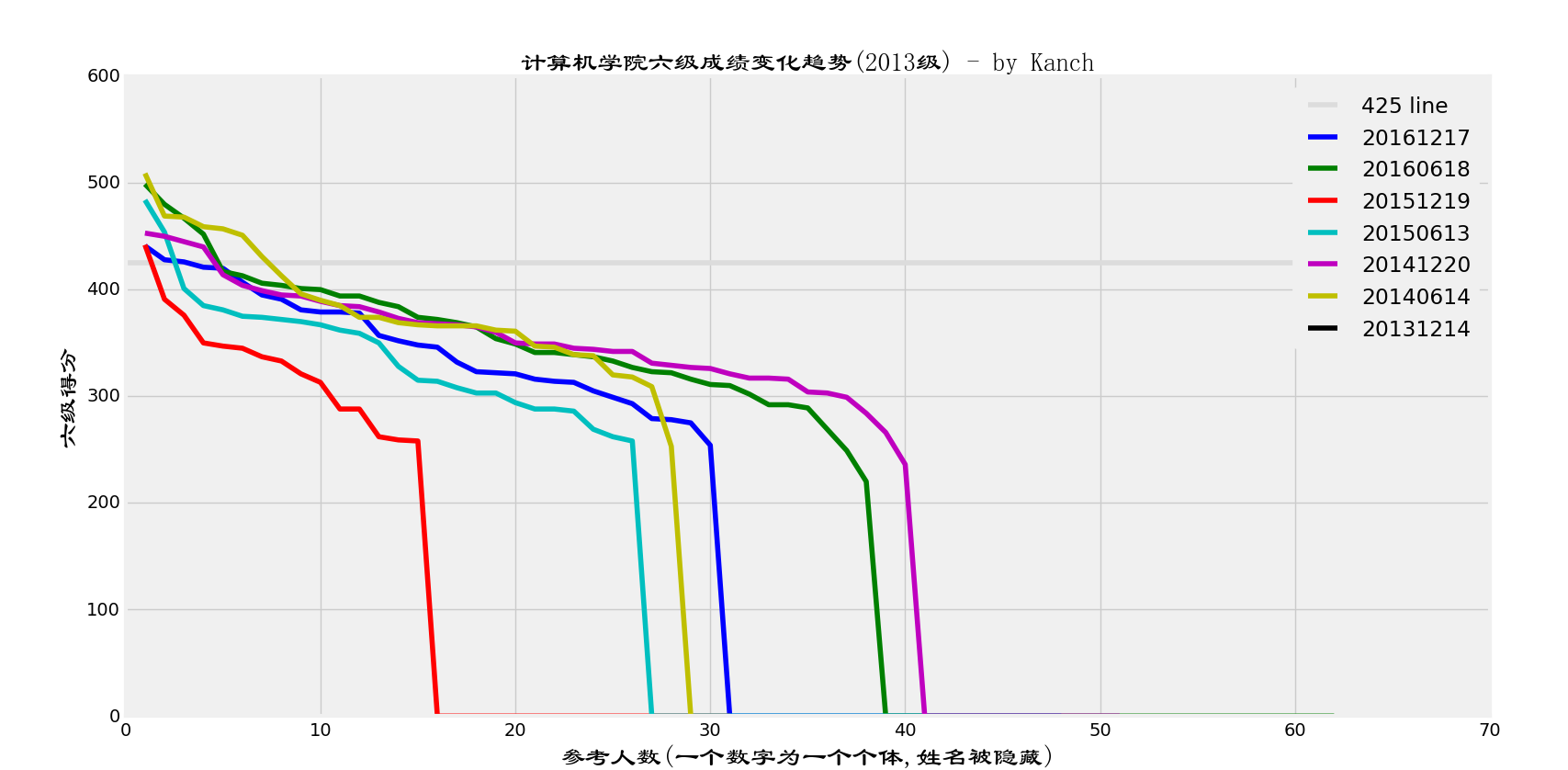
可以看出,六级成绩的每一年的总体变化是有很大的浮动的,我怀疑这和六级得分机制有关,不是说是什么相对分嘛。另外,不知道是不是2015年12月那次的六级特别难还是怎么的,通过的人数怎么那么少….
同样的,我们通过一样的方法得到历年计算机学院2013级的六级过级率情况
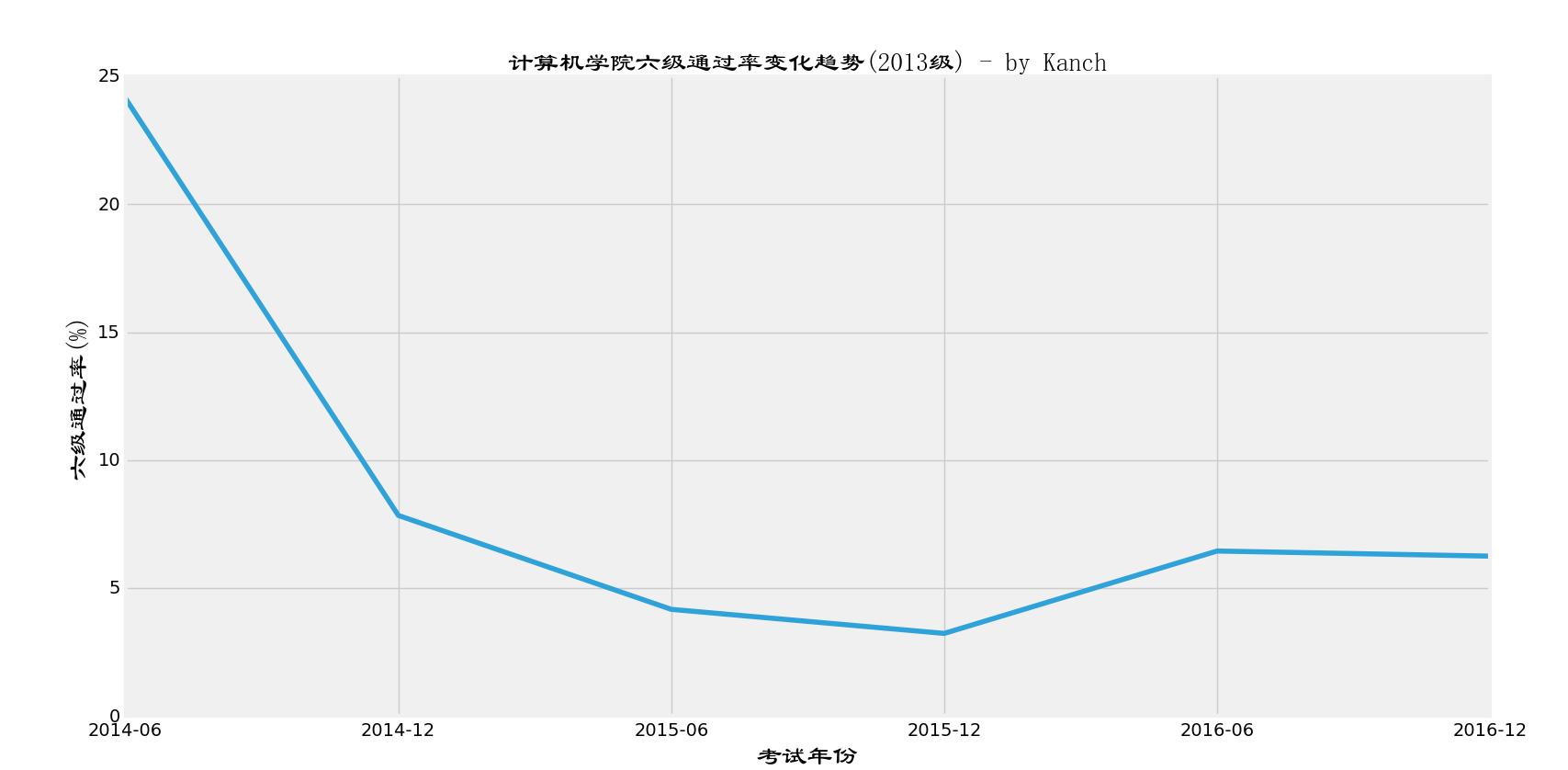
六级仍然存在和四级一样的情况,越到后面过级率越来越低。原因肯定同上的啦。
接下来是最高分以及最低分情况
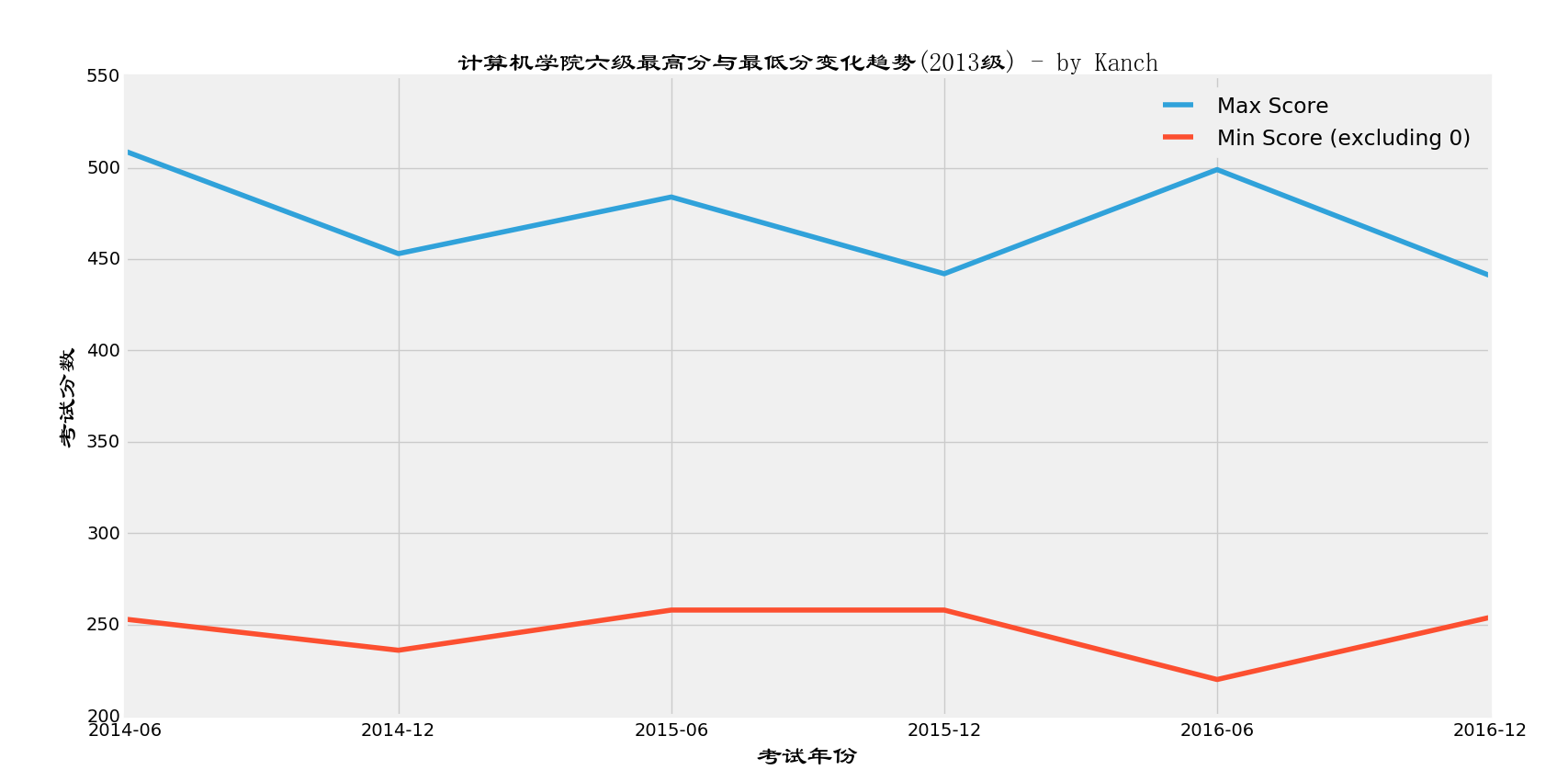
可以发现,六级的最高分波动不大,最低分就不讲了。我认为,六级成绩波动不大的原因是,大家都过了四级,说明吧,理论上讲,在一定程度上英语基本(最基本的哦)能力还是有的,再加上做题的时候来一点小聪明,分数就上去了。。。
计算机学院2013级,2014级,2015级同时期情况对比
以下对比了2013级,2014级,2015级,2016级第一次入学考试四级考试的通过率:
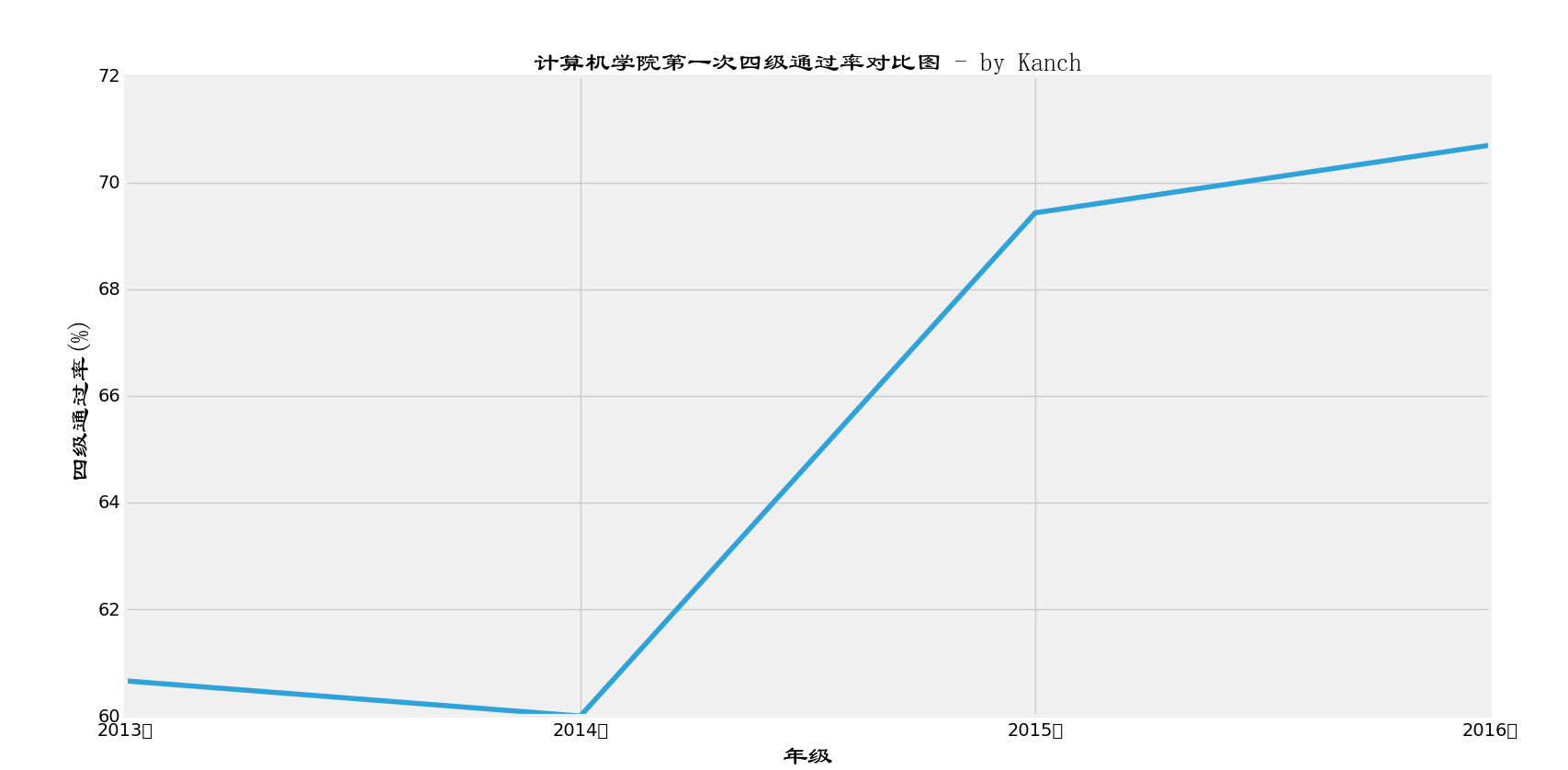
从上面这张图来看,分布是挺正常的,2015级开始是一本招生(在四川)而一大部分学生都来自四川,故2015级和之后的2016级通过率都非常高。之前的2013级和2014级通过率在当时看来,也都处于一个正常水平。
接下来是这几个年级平均分,最高分,最低分情况:
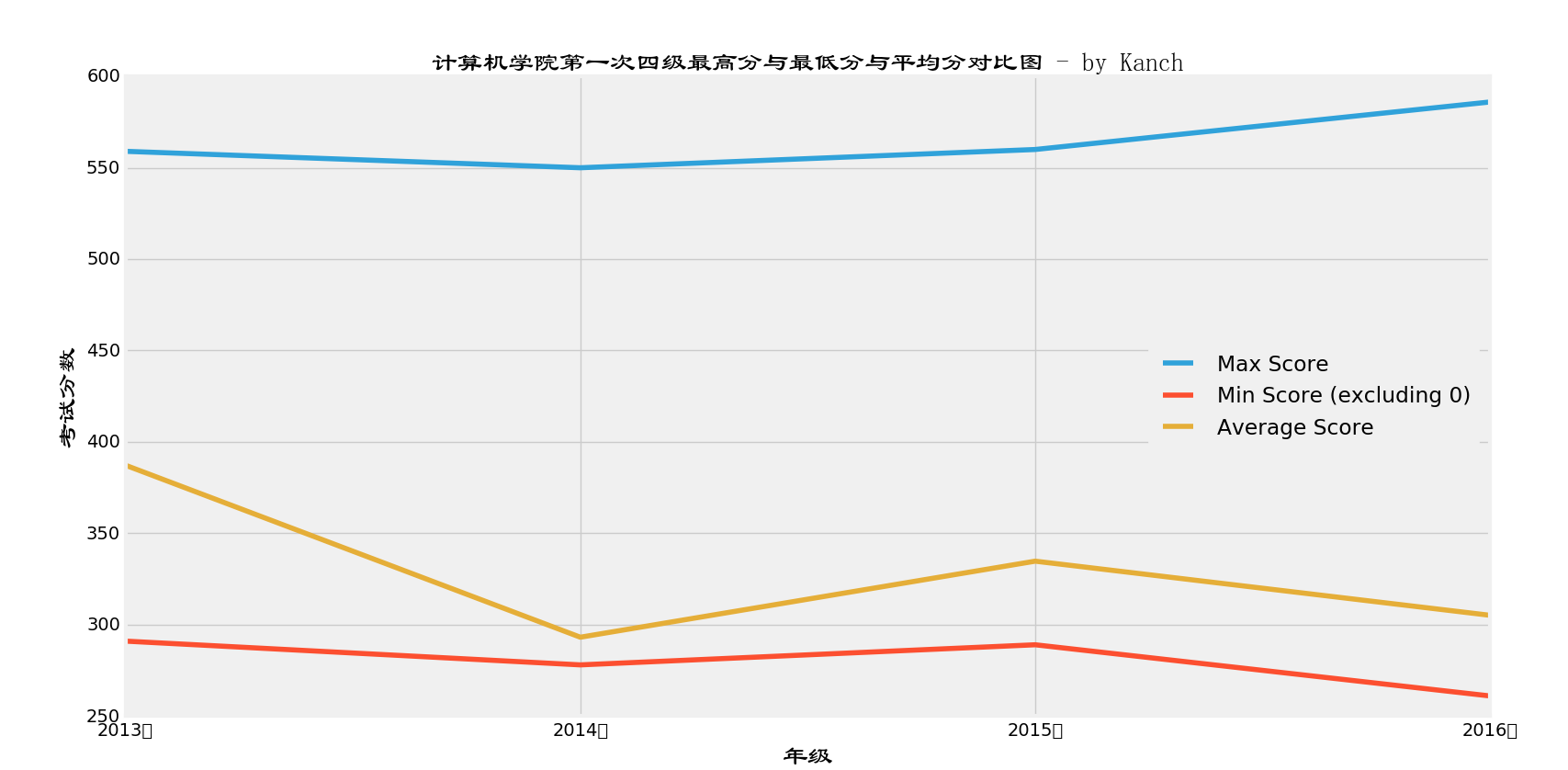
上图为包含0分的平均分,下图为不包含0分的平均分:
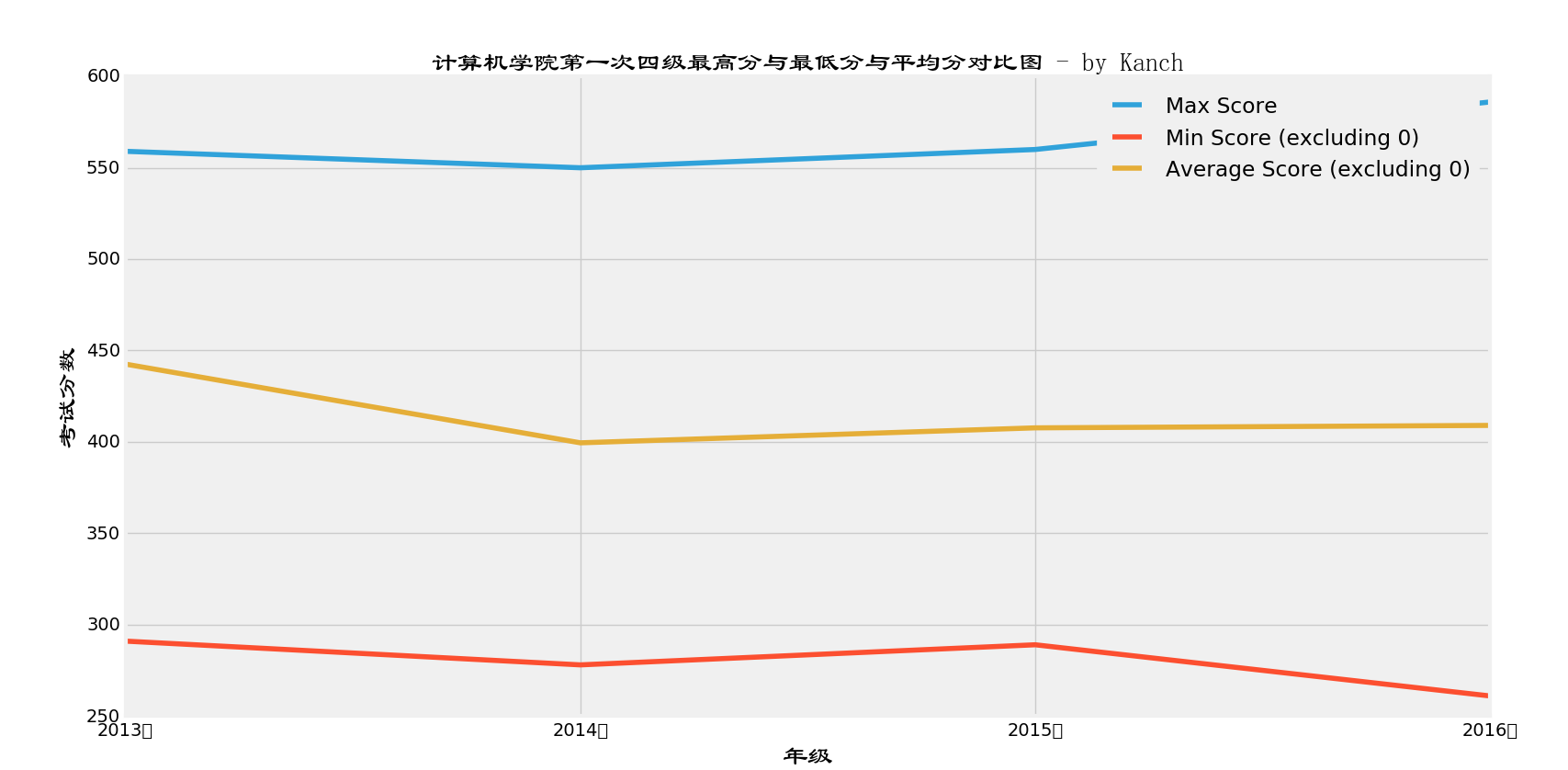
难以置信,居然,2013级的平均分那么高。怀疑那时候是不是考四级不要求高考英语必须多少分嘛。
看最高分,挺正常的,因为2016级也是一本招生,且高考平均分比我们2015级还高一些,所以,英语最高分高也挺正常的。不过吧,2014,2015,2016级的平均分全都没超过425…..然而通过率却高达69%,说明蛮多的人是挂线过的。
单独分析2015级的数据
下面是计算机学院2015级的四六级成绩变化情况:简单地讲,就是越到后面越不容易通过。上500也就更难了(至少在我们学校。)
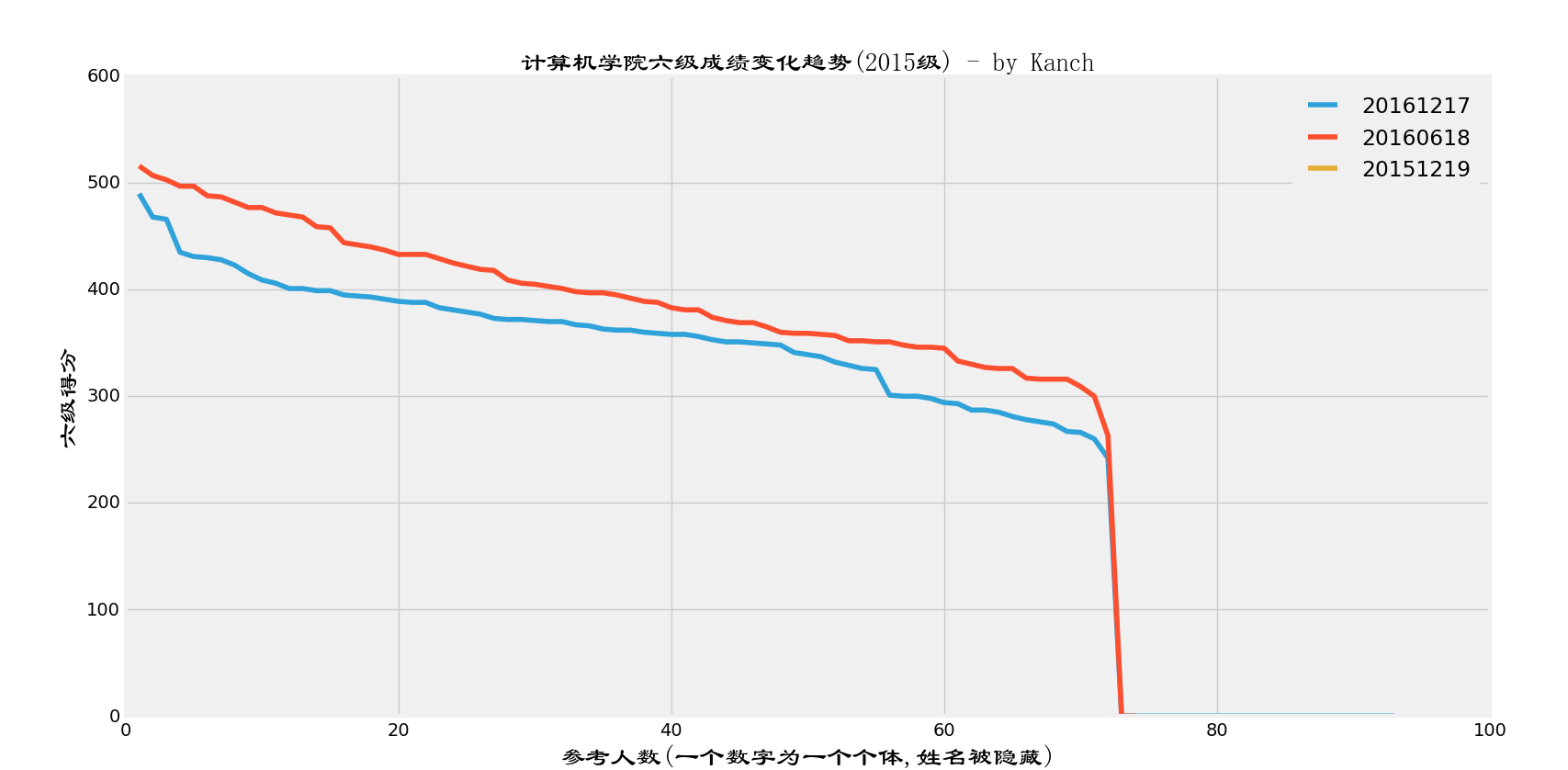
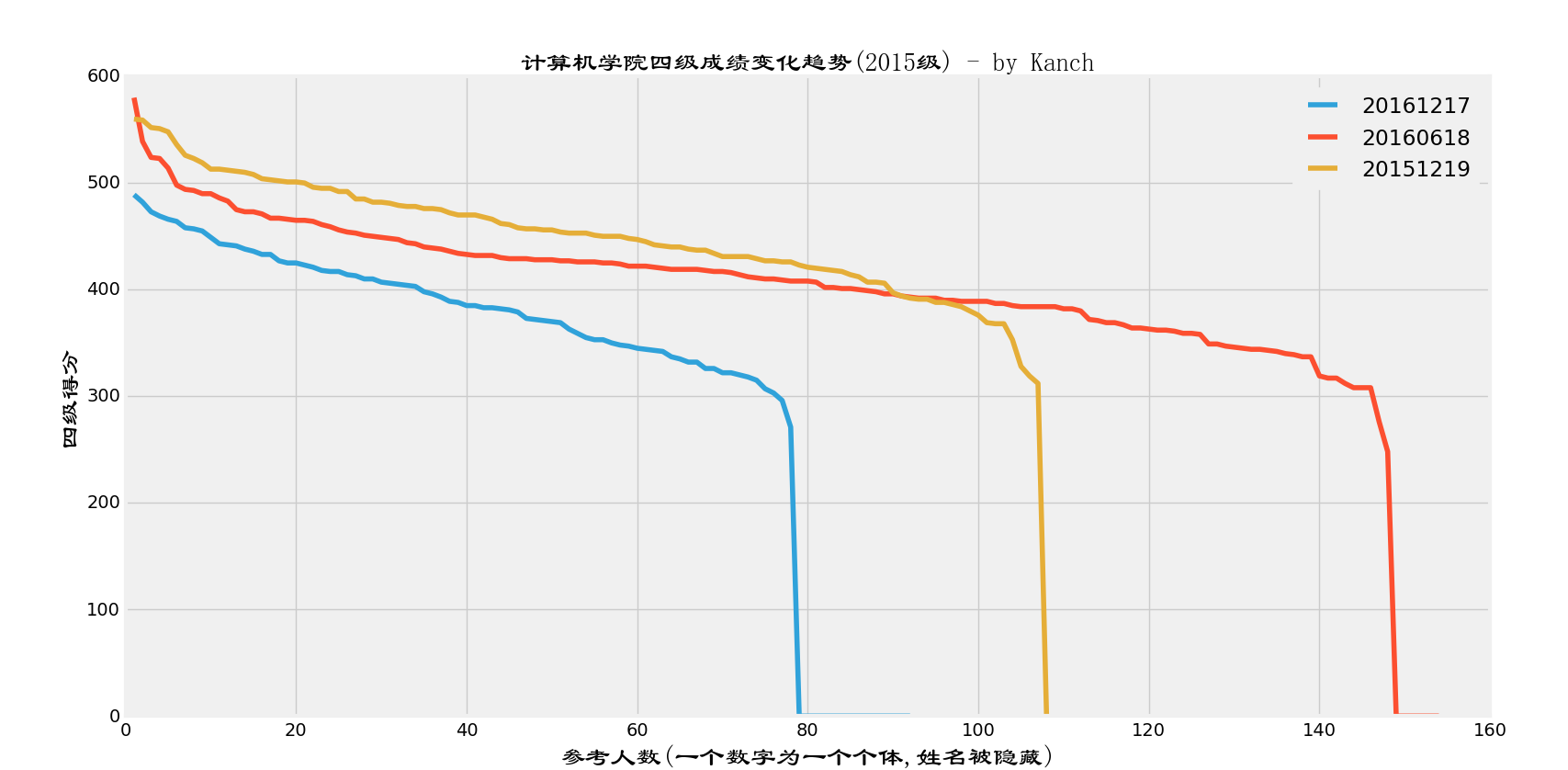
(完)
4.其它
大学真好玩,过四六级请趁早
这篇文章就当是拿到那些数据练练手外加提升自己一点小能力了。
毕业后更新(20190817)
一直到毕业,都还有人没过四级。虽然学生手册要求学位证需要四级425分及以上,不过最后都可以走特殊授位渠道。最后一学年(大四),随随便便哪个奖学金就可以走特殊授位了,而大四这一学年的奖学金都是优先给毕业资格不足的人。(仅适用于计算机学院)
© kanch → zl AT kanchz DOT com
last updated on 2022-07-27 01:57:54 +0000