hcnak.blog
posted at 2017-09-27 00:03:01 +0000
图像中的字符定位与分割(Python实现)
假设我们有如下图像:
现在我们想要将图片中的数字一个一个分割出来。得到一系列的如下图象:
本文同时使用Python和C++实现了以上图像分割。
灰度化图象
在处理之前,我们首先应该将图像去RGB,即在它对应的灰度图像上进行处理。我们可以使用opencv python库中的cvtColor函数来实现到灰度图像的转换。转换代码以及转换结果(归一化后)如下:
grayscaleimg = cv2.cvtColor(rawimg,cv2.COLOR_BGR2GRAY)
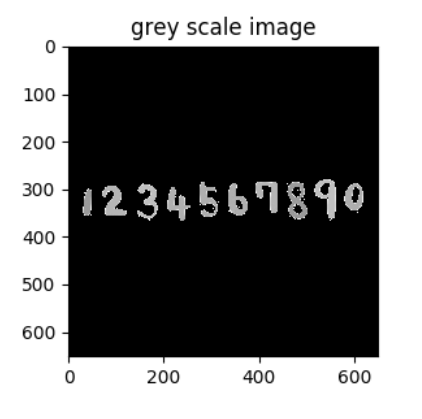
归一化图象
然后,我们需要对图片进行归一化,这样可以减少最后分割出的数字中的噪声:
grayscaleimg = grayscaleimg - int(np.mean(grayscaleimg))
grayscaleimg[grayscaleimg < 50] = 0
这里我们采取了对每个像素减去图像总像素的平均数,并设置阈值50以下的像素归零来实现归一化,归一化后的图像即上图所示。
寻找分割边界
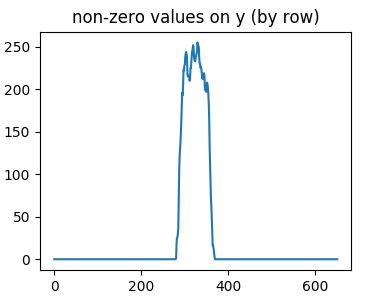
接下来,我们需要确定分割边界,由于我们已经将背景的像素值归一化为0,我们只需要对图像分别从x方向(列扫描)和y方向(行扫描)进行扫描,统计每一行/列的0和非0值的个数即可。统计完毕绘图如下:
y方向上:
x方向上:
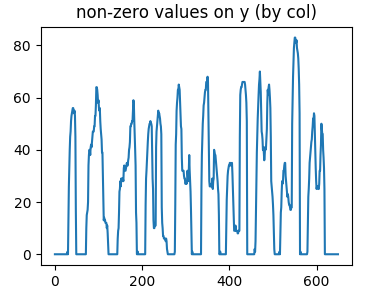
我们可以看到,行扫描结果让我们了解到了数字在y轴方向上的上下限,列扫描帮助我们了解到了每个数字之间的间隔位置(即值为0的地方,右图波谷)。在下图中,y方向那张图对应下图红色之间的部分,x方向图中的波谷(值为0的部分)对应下图中的橙色线段。
开始分割
接下来,我们只需要将图像从y方向切割出来,再遍历x方向的所有临界点(即从非零值到零值,或者从零值到非零值的点),即可切分出字符。
-
如果图像中的问题连着一起的怎么办?
设定一定的阈值,当某列的非零值小于该阈值,则认为此列为黏带列,应该从这里分割。
完整Python代码
from matplotlib import pyplot as plt
import numpy as np
import cv2
rawimg = cv2.imread("./test.jpg")
rawimg = rawimg - 246
fig = plt.figure()
fig.add_subplot(2,3,1)
plt.title("raw image")
plt.imshow(rawimg)
fig.add_subplot(2,3,2)
plt.title("grey scale image")
grayscaleimg = cv2.cvtColor(rawimg,cv2.COLOR_BGR2GRAY)
plt.imshow(grayscaleimg,cmap='gray')
# counting non-zero value by row , axis y
row_nz = []
for row in grayscaleimg.tolist():
row_nz.append(len(row) - row.count(0))
fig.add_subplot(2,3,3)
plt.title("non-zero values on y (by row)")
plt.plot(row_nz)
# counting non-zero value by column, x axis
col_nz = []
for col in grayscaleimg.T.tolist():
col_nz.append(len(col) - col.count(0))
fig.add_subplot(2,3,4)
plt.title("non-zero values on y (by col)")
plt.plot(col_nz)
##### start split
# first find upper and lower boundary of y (row)
fig.add_subplot(2,3,5)
plt.title("y boudary deleted")
upper_y = 0
for i,x in enumerate(row_nz):
if x != 0:
upper_y = i
break
lower_y = 0
for i,x in enumerate(row_nz[::-1]):
if x!=0:
lower_y = len(row_nz) - i
break
sliced_y_img = grayscaleimg[upper_y:lower_y,:]
plt.imshow(sliced_y_img)
# then we find left and right boundary of every digital (x, on column)
fig.add_subplot(2,3,6)
plt.title("x boudary deleted")
column_boundary_list = []
record = False
for i,x in enumerate(col_nz[:-1]):
if (col_nz[i] == 0 and col_nz[i+1] != 0) or col_nz[i] != 0 and col_nz[i+1] == 0:
column_boundary_list.append(i+1)
img_list = []
xl = [ column_boundary_list[i:i+2] for i in range(0,len(column_boundary_list),2) ]
for x in xl:
img_list.append( sliced_y_img[:,x[0]:x[1]] )
# del invalid image
img_list = [ x for x in img_list if x.shape[1] < 5 ]
# show image
fig = plt.figure()
for i,img in enumerate(img_list):
fig.add_subplot(3,4,i+1)
plt.imshow(img)
plt.imsave("./result/%s.jpg"%i,img)
plt.show()
C++实现
同时,我也实现了C++版本(未使用任何矩阵库),Github地址:https://github.com/ankanch/image-processing-practice/blob/master/charsplit/C%2B%2B-implements/TextExtractor.h
© kanch → zl AT kanchz DOT com
last updated on 2022-07-27 01:57:54 +0000